|
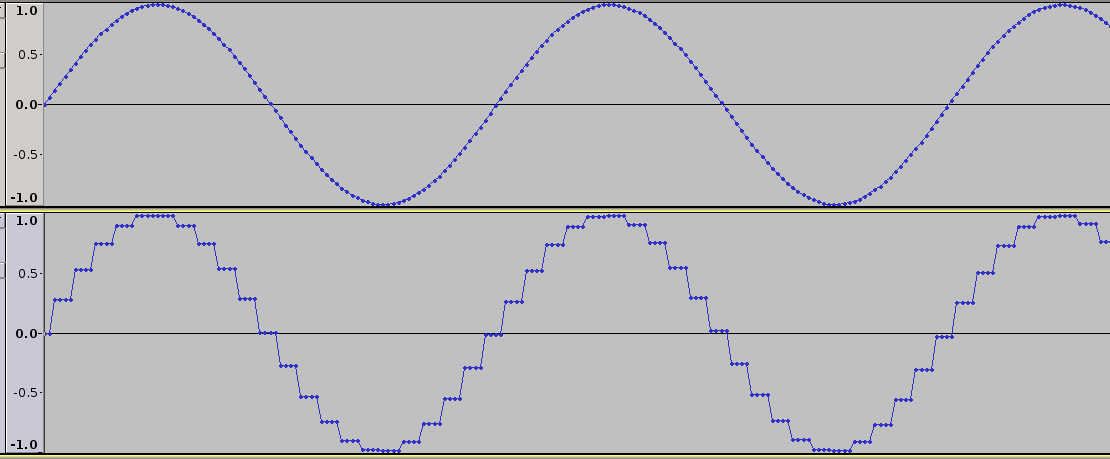
% SUBSAMPLING
%number of repetitions (1 -> original)
nr = 4;
disp(['number of repetitions = ' num2str(nr)])
% efect of sampling change N and Fs
f = 500;
Fs = 44100;
T = 2; %duration
y = 0.1*0.99*sin(2*pi*f*linspace(0,1*T,Fs*T));
%total length
tl = size(y,2);
fprintf('Number of sampling points = %d\n',size(y,2));
y = [y,zeros(1,nr)];
y = y( nr*floor([0:tl-1]/nr+0.5)+1 );
sound(y, Fs)
|
%
AMPLITUDE QUANTIZATION
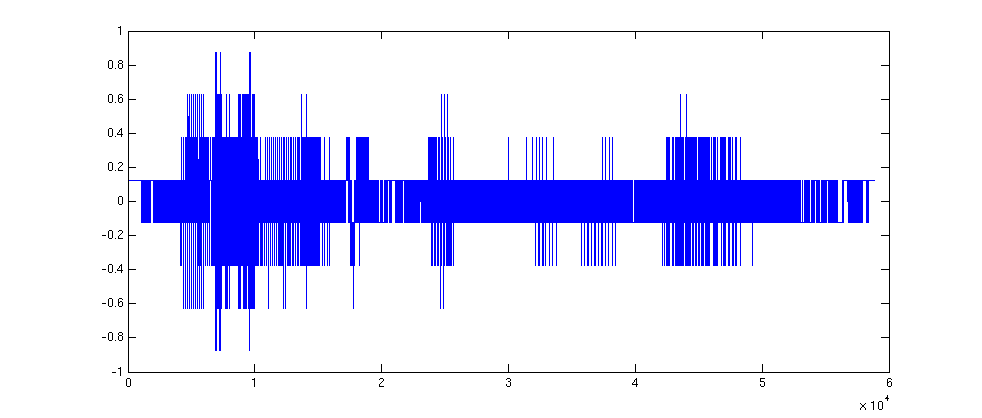
%number of levels
nr = 2;
disp(['number of levels = ' num2str(nr)])
delt = 2/nr;
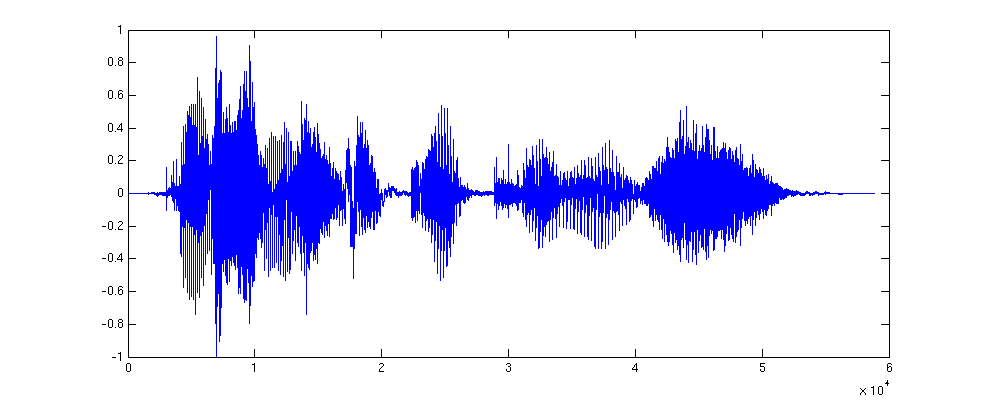
% Read file
filename = 'input.wav';
[y,Fs] = audioread(filename);
% stereo -> mono
y = y(:,1);
% adjust volume
v = max( max(y),-min(y) );
y = y/v*0.999999;
figure(1)
plot(y)
% quantize
y = delt*floor((y+1)/delt)+delt/2-1;
disp('The levels are:')
disp(unique(y))
figure(2)
plot(y)
sound(y,Fs)
audiowrite('OUTPUT.wav',y,Fs);
|